这里看到一个业务需求是将Nginx环境中将蜘蛛和爬虫的请求和用户的请求分离不同的后端。比如我们可以预先设定爬虫的记录,然后在符合要求的爬虫和不属于的时候进行分离。这里简单的记录如下。
1、用map来匹配变现
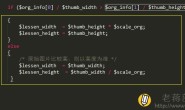
map $http_user_agent $is_bot {
default 0;
~[a-z]bot[^a-z] 1;
~[sS]pider[^a-z] 1;
'Yahoo! Slurp China' 1;
'Mediapartners-Google' 1;
'YisouSpider' 1;
}
在这里我们生成了一个名为 $is_bot 的变量,该变量默认值是 0 ,如果匹配到上述 4 种正则表达式的情况后,值就变成1。你可以继续往 map 中添加新的表达式规则。
2、在location中使用该变量
location / {
error_page 418 =200 @bots;
if ($is_bot) {
return 418;
}
proxy_pass http://donkey_web;
include proxy.conf;
access_log /export/home/logs/donkey/access.log main;
}
3、@bots的定义
location @bots {
proxy_pass http://donkey_spider_web;
include proxy.conf;
access_log /export/home/logs/donkey_spider/access.log main;
}
当判断当前请求是爬虫的时候,返回 418 错误码。通过 error_page 将 418 错误码改为 200 (正常请求响应码),然后进入 @bots 这个 location 进行下一步处理。@bots 中将请求反向到你指定的后端应用。
如此便可将正常的用户访问和爬虫访问独立开来,使二者不会互相影响。
参考来自:http://www.cnblogs.com/91donkey/